Background
At my current workplace I was tired of using an obsolete python 3.6 and decided to focus on upgrading python to something more recent, 3.10. My main reasoning was to improve dev-experience in using modern tooling and language feature. Also, bug fixes and safity patches.
It turned out, one of the side-effects of this upgrade was enable non-CUDA machine learning inference with a noticible perfomance boost.
This article will tell you about this side-effect and may also help you to convince your collegues on why upgrades are important.
Difficulties of upgrade
There is a bunch of problems I faced when I started the transition.
At this time we used quite an old Ubuntu 16.04 version and lead to some libraries were not available in public repos. The most critical ones were CUDA related libraries.
But why should I bother about CUDA at all? Well, because we’re using onnxruntime for machine learning inference. The version of this library is tightly bound to two things: the version of python and the version of CUDA toolkit. If I want to upgrade python I need to upgrade onnxruntime and inevitably CUDA.
At the time of the transition the only supported versions of ubuntu for CUDA were 20.04 and 22.04.
That’s a bummer.
I was puzzled if I should continue the transition, since one of the most important parts of our system is not available. The tough thoughts led me to a very dirty, but working solution.
I opened the instruction on installing CUDA toolit locally and noticed a pattern in how URL to downloading was built.
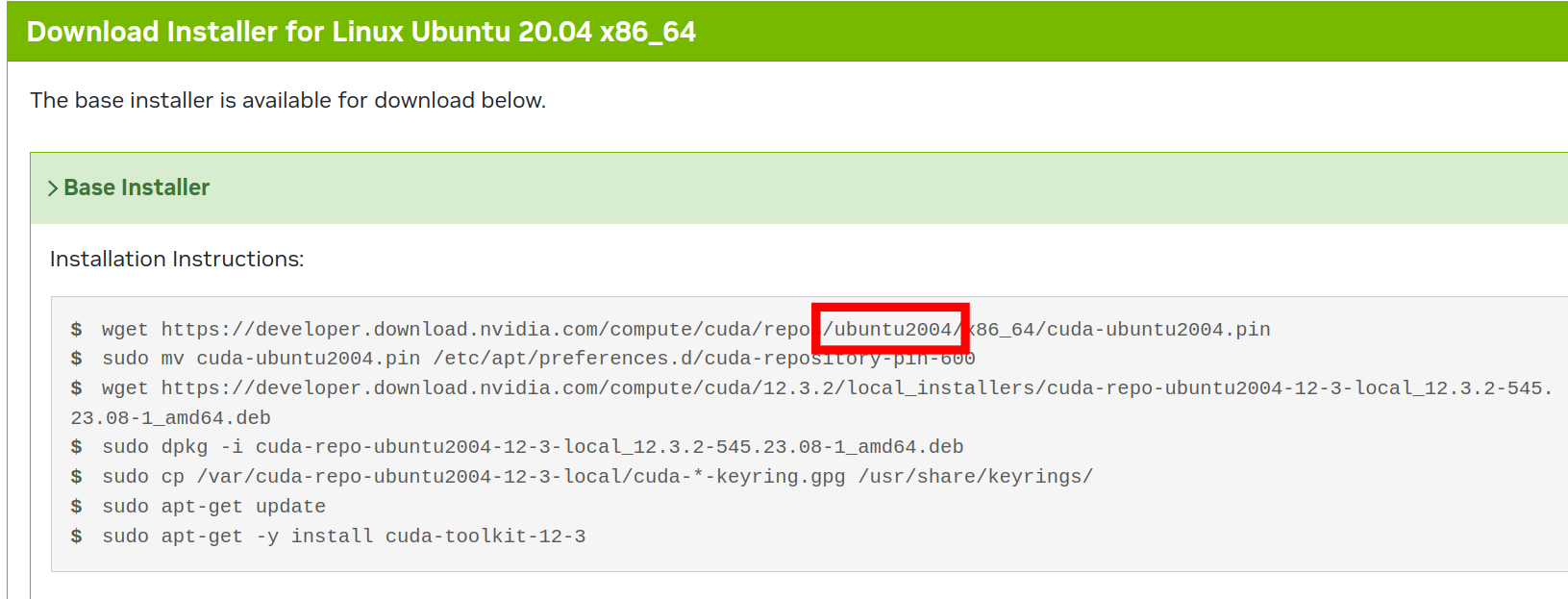
I built an URL for ubuntu 16.04 in the same manner and voilà! It worked!
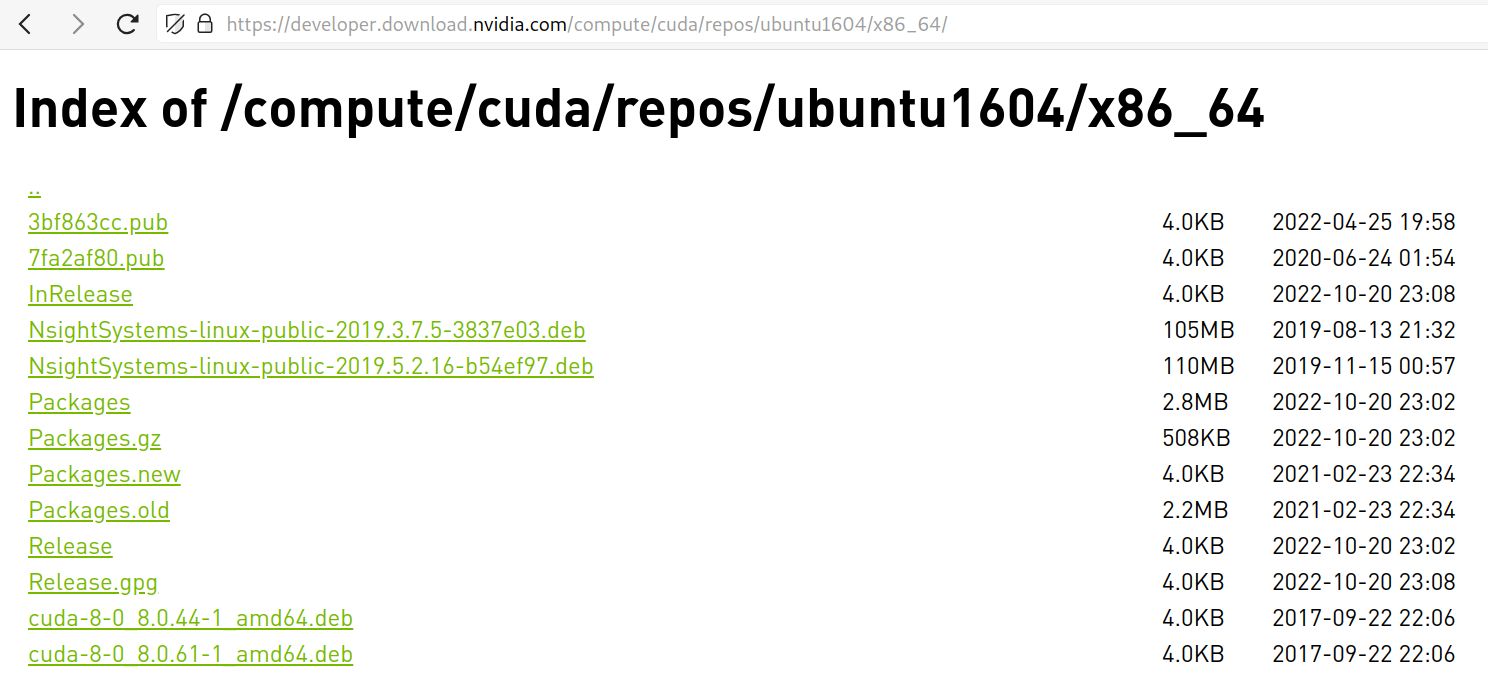
After some back-and-forth (upgrade linux kernel and gcc) I was able to upgrade CUDA toolkit and install onnxruntime compatible with new python!
Show must go on!
Metrics
Let me give a little bit of context regarding metrics.
Whenever you’re doing anything regarding performance, you first need to find a reasonable way to measure this performance.
In our case, we had an exact place where the actual “work” was done. Measuring the time it takes us to run this code would be perfect because, in the end, it’s much easier for me to compare statistics from one place than trying to optimize several ones.
I was fortunate to have an exceptional engineer, Georges Dubus, who already brought to our project Open Telemtry stack.
The only thing left to me is to introduce a few “flags” to distinguish metrics from different setups.
Old CUDA vs new CPU
To this moment I had two setups: one running old python and one running new. More over, I made it in the way, so I can quickly switch between different Execution Providers.
After the first banch of benchmarks I was not going to belive it.
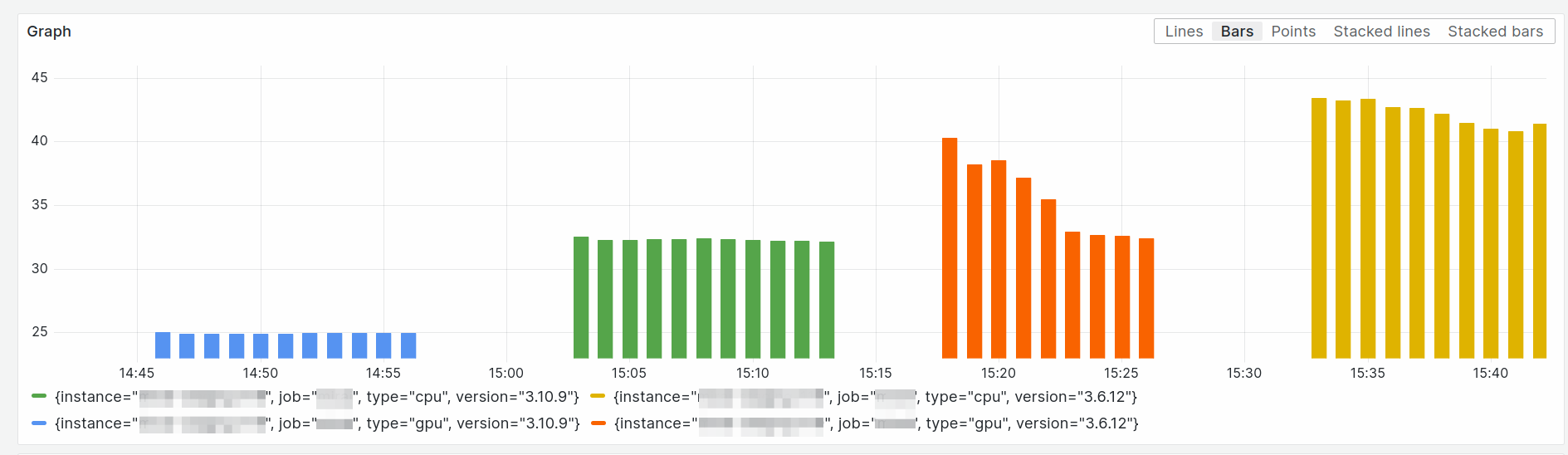
The performance of a default CPU provider with newer version was roughly equal to the performance of CUDA/GPU provider with the older one.
Bigger model
I ran these benchmarks on a different setup, but the numbers were quite similar.
Sounds good, right? Well, yes, until I tested an inference of a bigger (deeper) machine learning model. Unfortunately, the performance of CPU Provider was not acceptable. So I begin the research on other options.
You may also ask me, if the performance of CUDA/GPU on a newer version was good enough, why didn’t I just chose this option. Unfortunately, as I mentioned above upgrade CUDA was quite a laborious work, required different steps executed in a very precise order. Therefore I didn’t try to fully avoid this option, but left it as a last resort.
OpenVINO
The hardware we using utilizes Intel CPU. Since after the python’s upgrade this CPU gives us a fair performance, can I squeze more from it?
The answer is yes. Intel made an open-source toolkit, called OpenVINO. The idea is very similar to CUDA: optimizing training and inference of machine learning models on vendor-specific hardware.
Lucky me, Intel already implemented an ONNX’s ExecutionProvider and even made pre-compiled wheels.
The changes I need to implement to benchmark is adding a new provider “OpenVINOExecutionProvider” and executing pip install onnxruntime-openvino.
The only thing left to me was to run benchmarks and compare results.
Unfortunately, I don’t have nice plots to show here, but here is as table consiting the statistics for the same metric I described above.
| provider | 99th percentile | Average |
|---|---|---|
| CPUExecutionProvider | 65ms | 49ms |
| CUDAExecutionProvider | 30ms | 21ms |
| OpenVINOExecutionProvider | 33ms | 24ms |
As you can see, the performance of OpenVINOExecutionProvider is roughly equal to CUDAExecutionProvider.
Conclusion
As you may already understood, I stick to the OpenVINO.
It was a bit of a journey and research, but in the end I brought an upgrade of the whole system and simplification of the requirements. OpenVINO runs on CPU, that means our product will run fully on CPU reducing the cost of the product! Something I didn’t expect when I started the upgrade.